
It all started with Andy and me thinking:
Tell me, on the phone keys. There is “A” equal to pressing [2] once, “B” is equal to pressing [2] twice, etc. And where the space is, we can choose: Key [0] or [1]. But if the [0] key is the space, how do you enter the character “0”?
Actually, you can easily decide the question by saying: just tap the [0] key twice. But I now felt like exploring this further and asked you, our users. And indeed, @radioscout answered – and unwittingly started an avalanche. He had three different mobile phones available for review: a Nokia, a Siemens and a Samsung.
Together we now tried to find out how the mobile phones actually worked. Where were the spaces, where were the special characters hidden? We soon realised that all three devices behaved completely differently. The key assignments were different, not only for the spaces, but also for the numbers and especially for the special characters. For example, we used to handle the order of the key assignments in this way:
- Basic letters (i.e. the letters that are usually printed on the keys, e.g. “ABC”).
- The digit of the key (in this case “2”)
- And then optionally a few special letters (here, for example, the Ä).
Well, the assignments of @radioscout revealed, however, that the digits not always come directly after the “basic letters”, as the example of the Samsung device shows:
2: A B C Ä Å Æ Ç Γ 2
It got even more interesting when you looked at upper and lower case. Here is the Siemens device:
2: a b c 2 ä à ç æ å
2: A B C 2 Ä Æ Å
As you can see, you can actually type different characters in lowercase mode than in uppercase mode.
Now my ambition was aroused and @radioscout was relentlessly grilled by me on all sorts of details. The most important one was: How do you actually change from upper to lower case? The older ones among you will remember: There were usually three different modes:
- “Abc”: The next typed character is upper case, all following characters are automatically lower case.
- “ABC”: All following characters are upper case
- “abc”: All following characters become lower case
Some devices still had a special mode for digits, sometimes even one for special characters.
It turned out that switching between these writing modes wasn’t simple to understand. In the first approach, we simply assumed that the three modes would simply cycle through. But the problems already started with the fact that the change key was sometimes a [*] and sometimes a [#]. And in fact, the sequence was not clear. Suddenly it turned out that there were special cases. For example, at the end of a sentence, it automatically jumps to “Abc”.
Now I wanted to know for sure and looted our donation account (at this point, as always, the warmest thanks for each of you who could contribute! If you still want to: https://blog.gcwizard.net/support-and-contribute/). I got some equipment to test through:


I immediately felt moved back in time:
Do you have a Nokia charger? – No, only Motorola or Siemens.
To be on the safe side, in case one of the devices stopped working, I had obtained several models from each manufacturer, if possible. It was to turn out to be both a blessing and a curse.
First I looked at the two Samsung devices (because I was able to start them without a SIM card; I had then been kindly provided with some SIM cards one by one by other users). These are the E1120 and the GT-E1170. Until now, I had been of the naïve opinion that at least the devices from the same manufacturer should work in the same way. But the first look at the two Samsungs revealed: the space is on the [0] on one device and on the [#] on the other. But if the space is on the [#], how do you change the write modes? Exactly, on the [*], while the other device uses the [#] not occupied by the space.
You guessed it: it turned out that really EVERY – SINGLE – DEVICE behaved differently.
The original plan to simply add special characters correctly to our vanity function melted away. Here it was clear: I needed a completely separate simulator for each device.
I now spent hours and hours trying to figure out how each phone behaved. There are models that switch back and forth between “Abc” and “abc” but without using “ABC”. There are some that go straight to “Abc” after a punctuation mark (?!.) and a following space, unless you were in “ABC” mode before. There are some that switch to “123” mode with a different key than to upper case mode. There are even devices where you can only enter the next mode if you press a key for a long time (which is of course difficult to code in the later tool, which is why it is not supported). Every device has its own quirks and we had to find them.
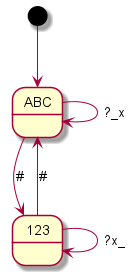
Here you can see the graphical representation of the mode changes (“?” indicates a punctuation mark, i.e. “.?!”, the underscore represents spaces or line breaks, the “*” or “#” – or just in one case the “0” – represent the mode change keys and “x” any other writable character):

Motorola CD930 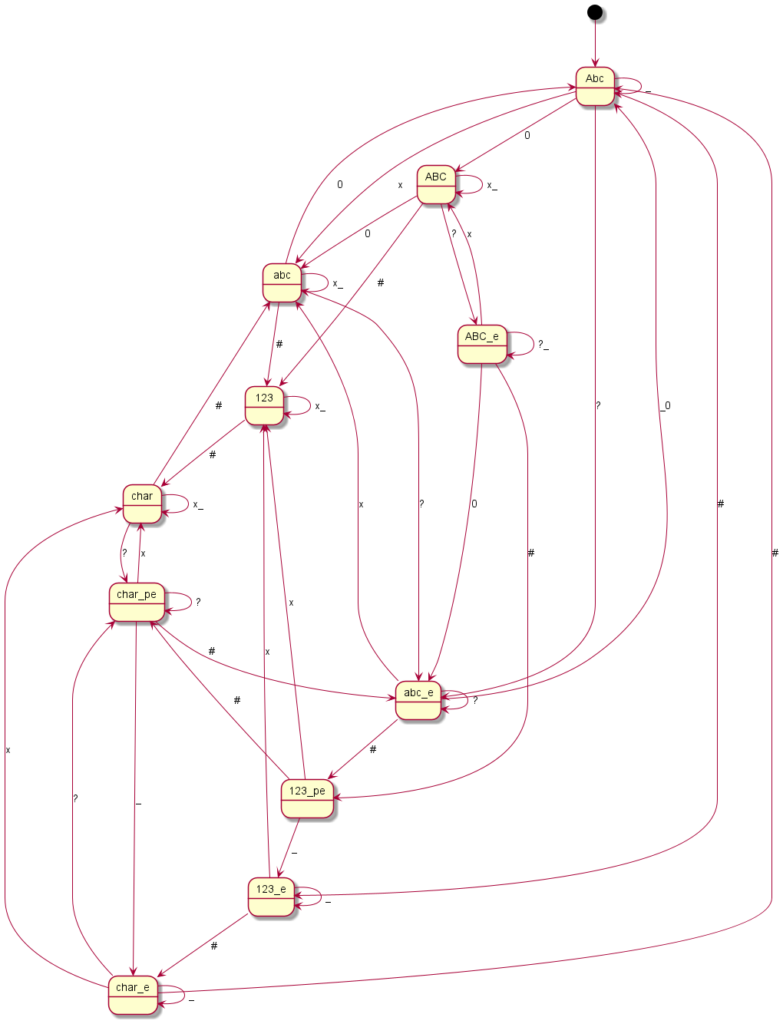
Motorola RAZR V3 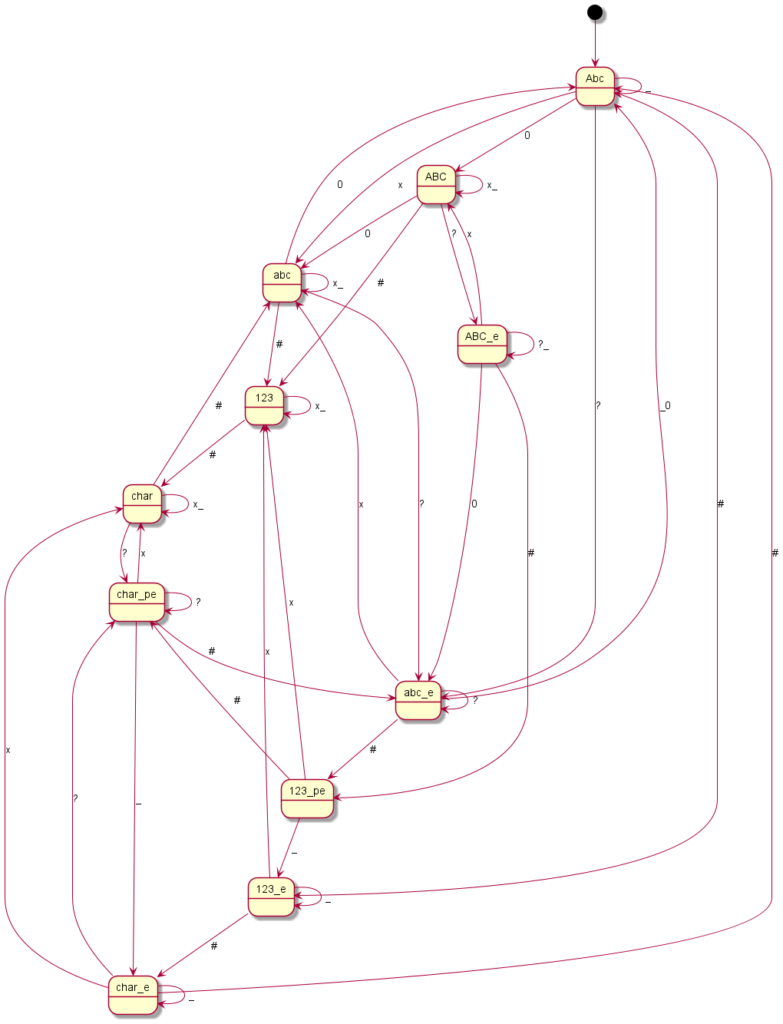
Motorola V600 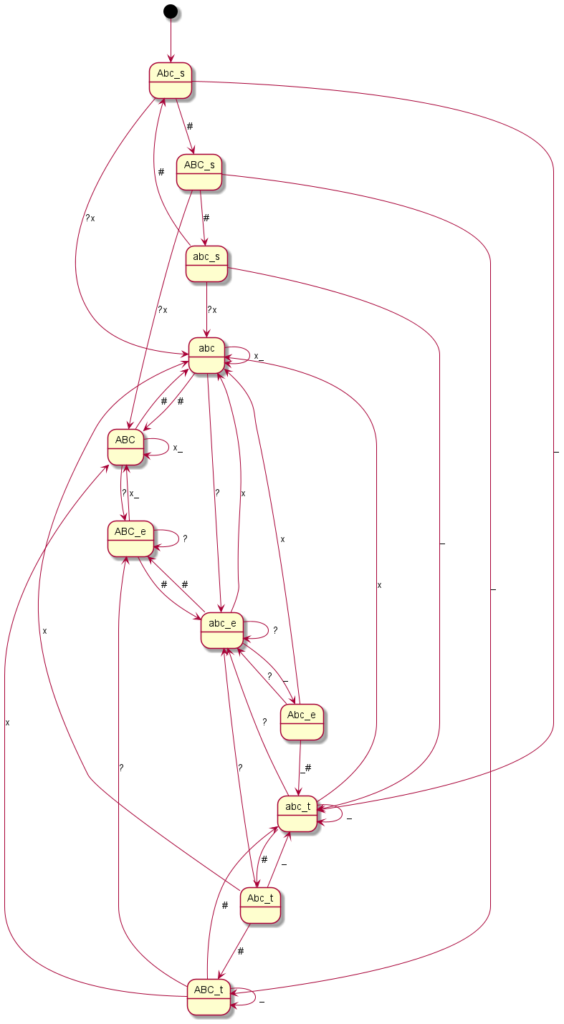
Nokia 1650 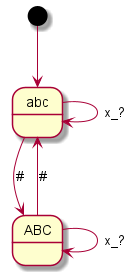
Nokia 3210 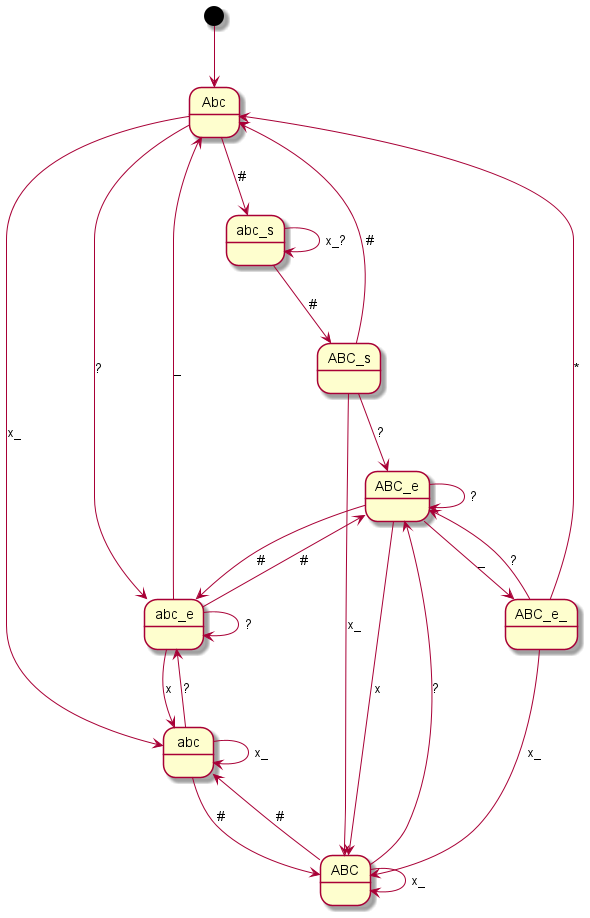
Nokia 3330 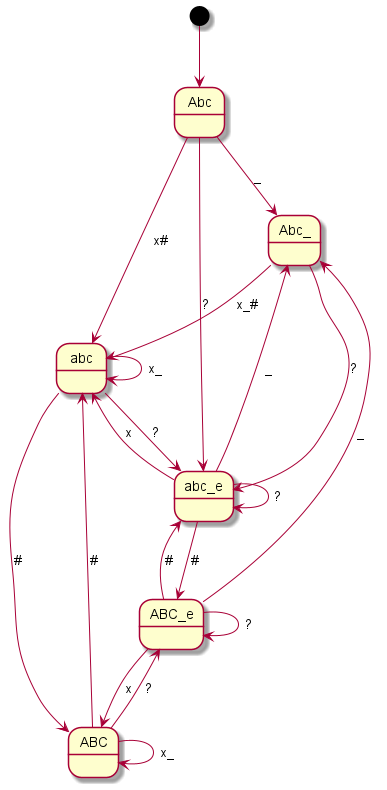
Nokia 6230 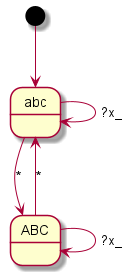
Sagem My X-3 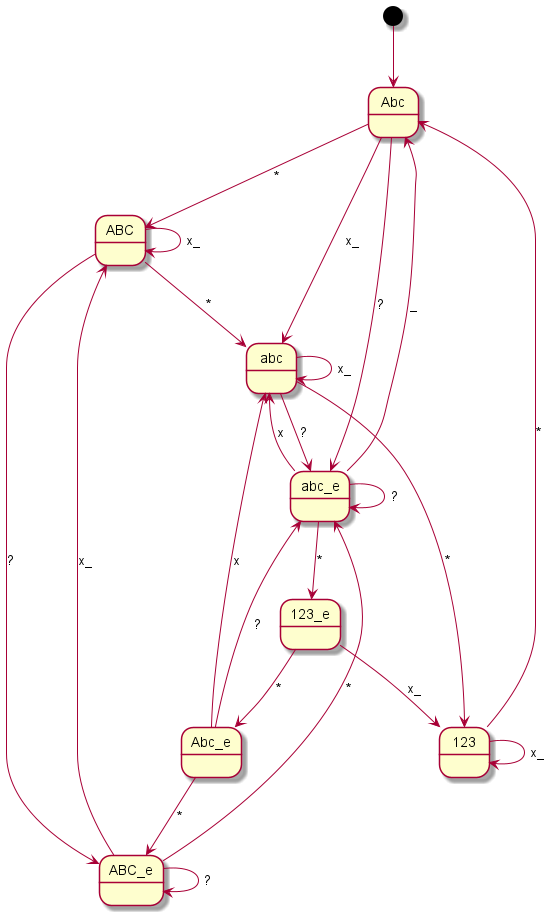
Samsung E1120 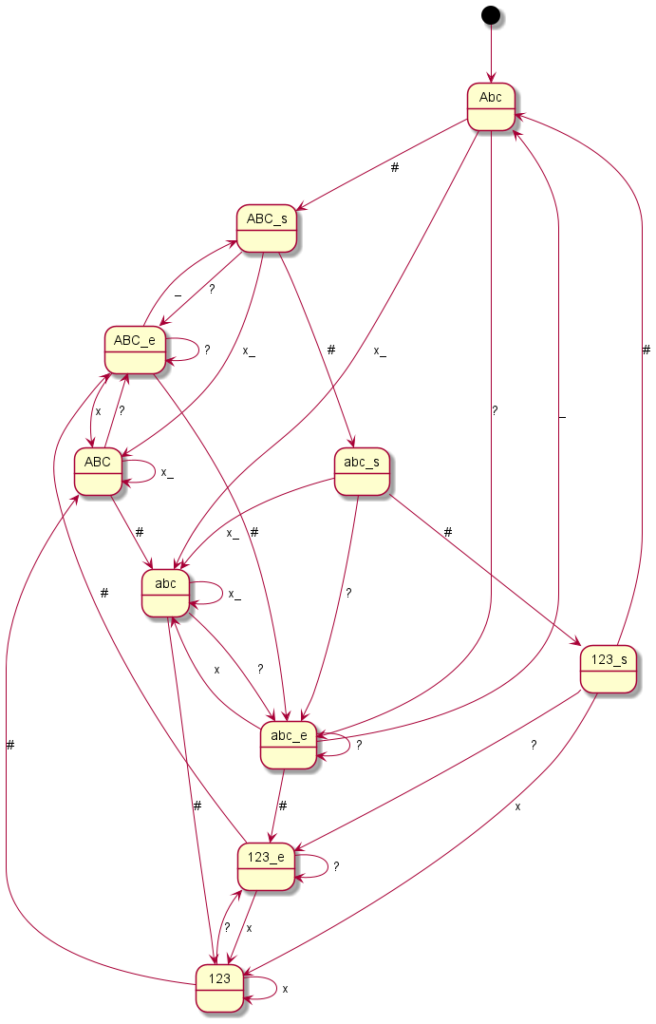
Samsung GT-E1170 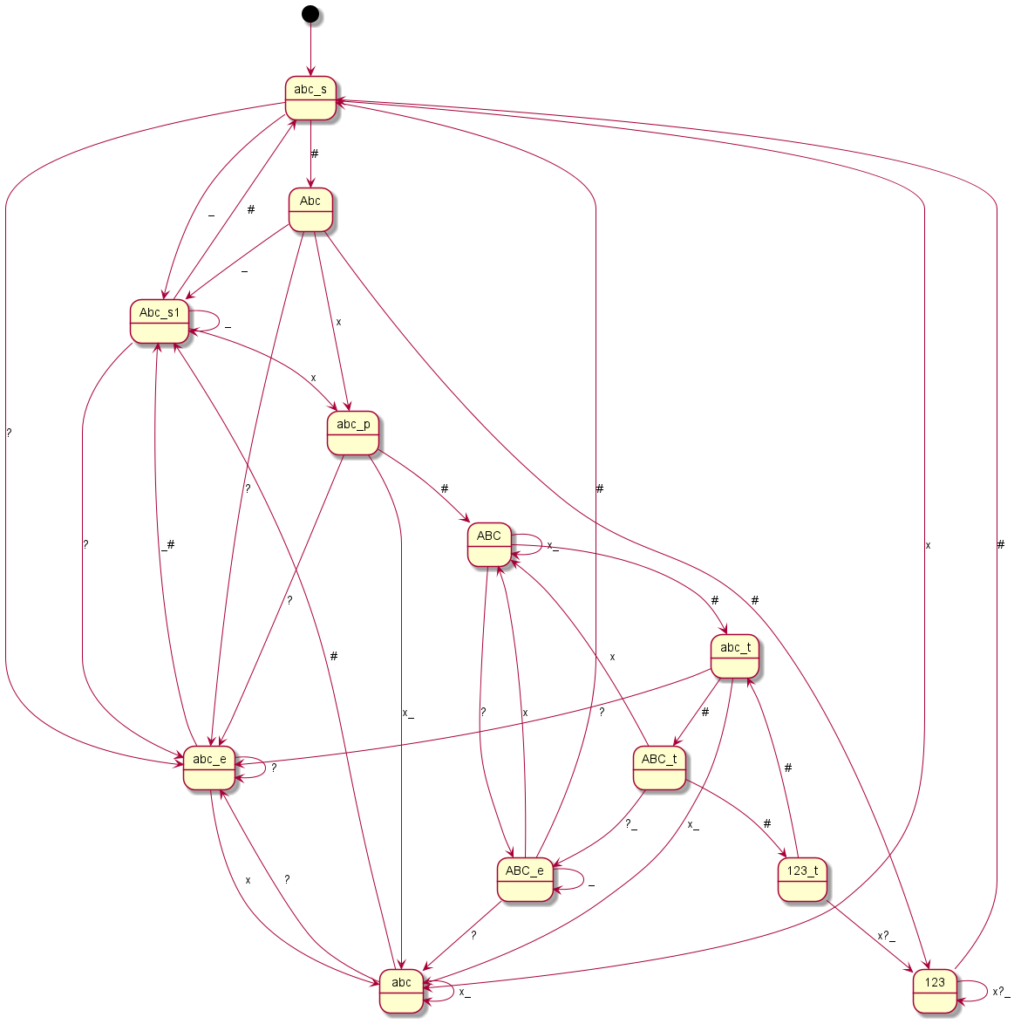
Siemens A65 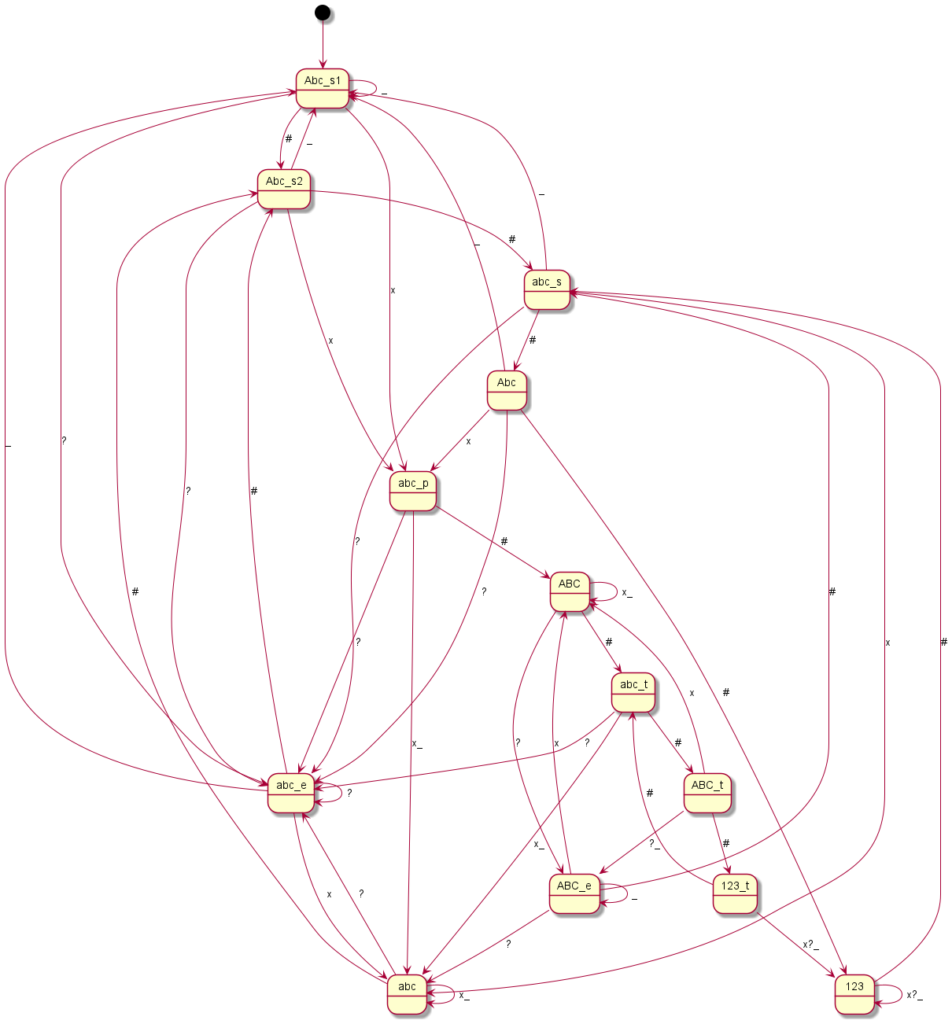
Siemens C75 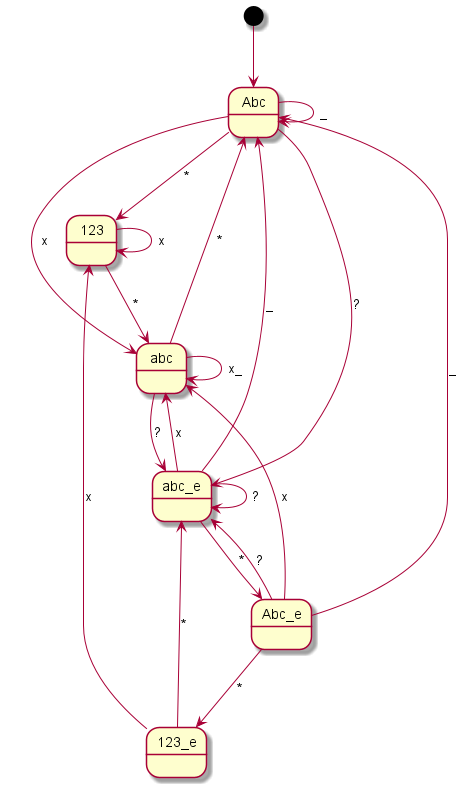
Siemens ME45 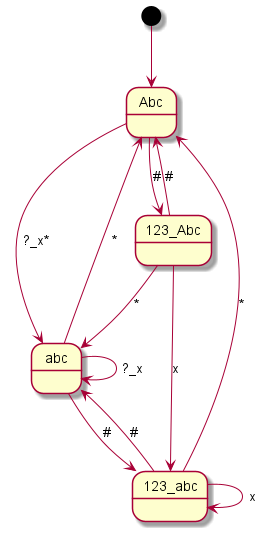
Siemens S35 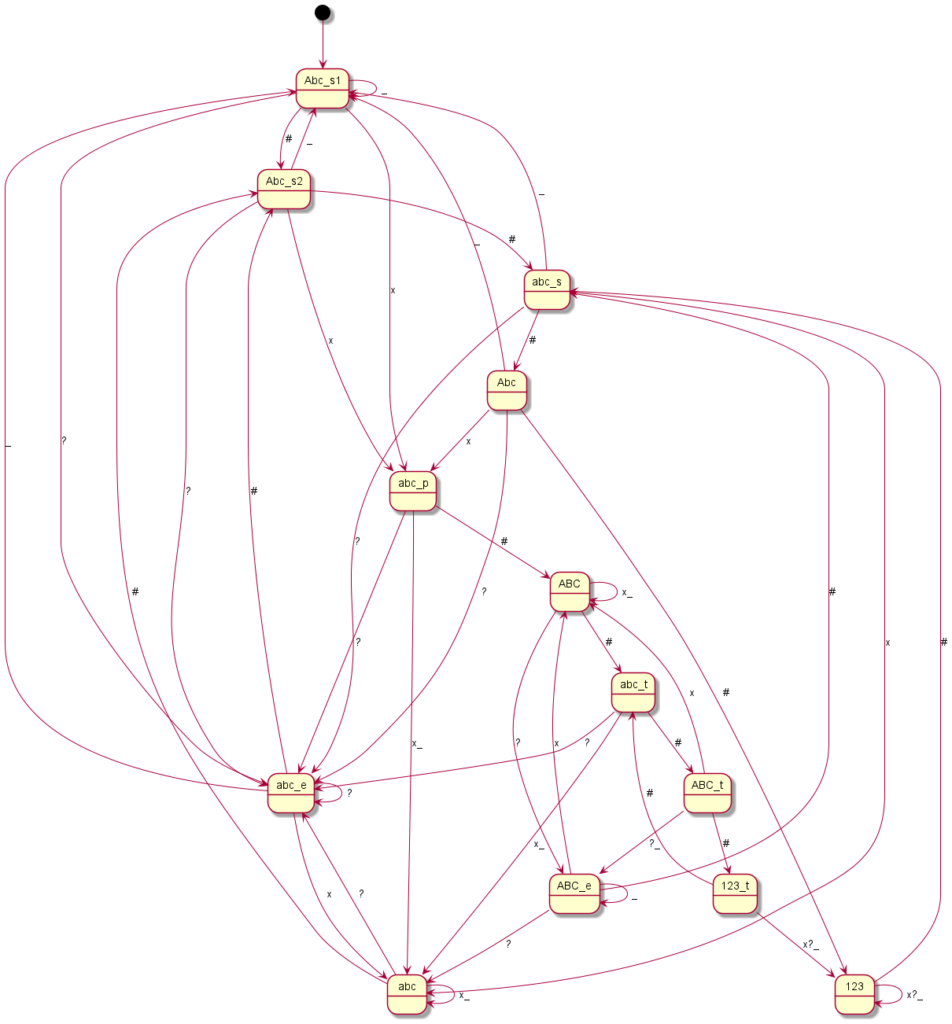
Siemens S55 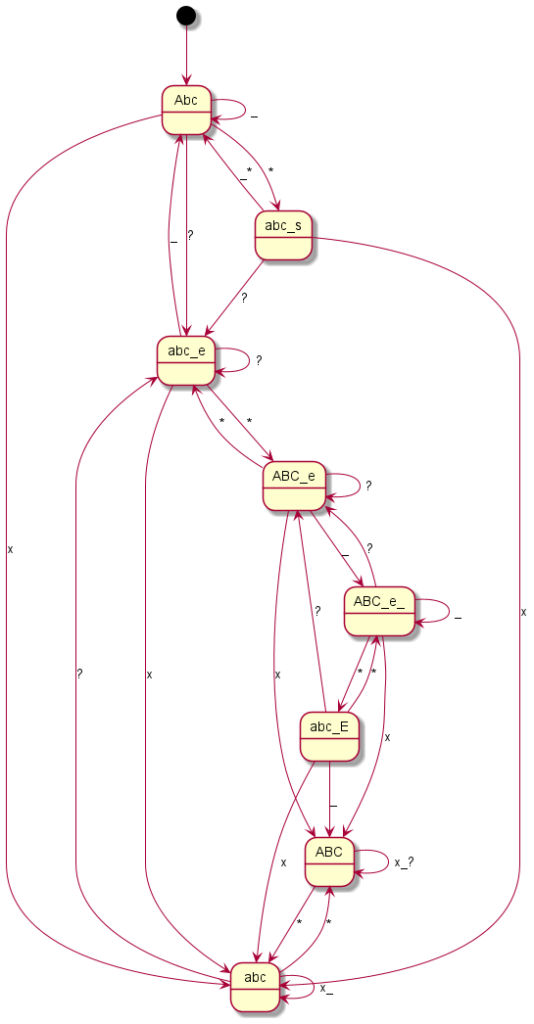
Sony Ericson T300 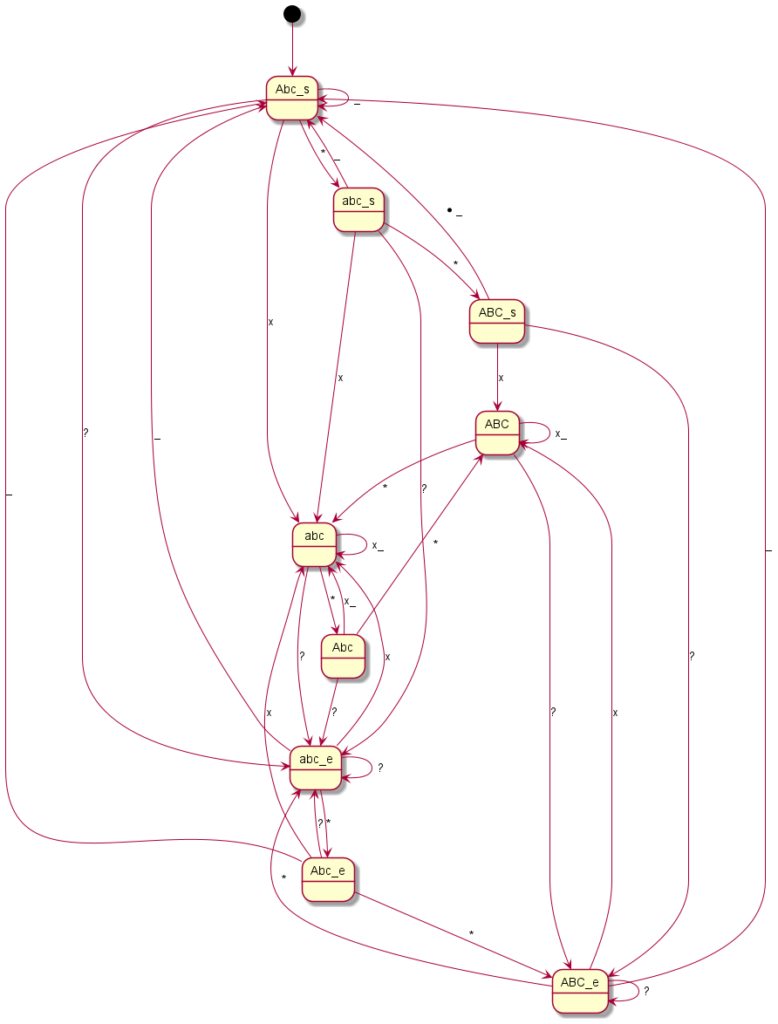
Sony Ericson K700i
Some of them are really freaky. For example, on a Siemens A65, you can only get to “ABC” mode if you have previously typed a letter from “Abc” mode, in which case you first switch to “abc” mode after typing. Or with the Siemens S55, you only get to “Abc” after a punctuation space combination if you do not write this combination directly at the beginning of the text.
Coding all this individually was definitely not my plan and so I said goodbye to our old code at this point. Until now, I had still believed that if you simply write in an exception here and there, you would somehow get there. But every single device is its very own exception. I then decided to programme something we call a “state machine” in computer science. Essentially, you define states. And you define how you get to these states and with which inputs you leave them to which states. You have just seen the graphical result. The boxes represent the states, the arrows show how to reach or leave them. At the arrows are the respective input characters that are necessary for the respective state change. Now I have to describe these states, so-called state graphs, for each device, but I only need exactly one universal code to make the whole thing work – namely the “universal state machine”. This simply takes a set of rules and then runs off the respective inputs; pretty much like humans do when they read one of the graphs.
Well, at some point I felt I had explored everything. Until I accidentally discovered the “input language” option on one device. I thought nothing of it. Will probably just be the dictionary for the word suggestions, I thought. Until I noticed that I could no longer type “Ä” in the newly selected language…
So the input behaviour is not only dependent on the manufacturer, no, not even on the specific model, but also on the selected input language!
In retrospect, it is quite clear: Turks naturally need different special letters than Germans, while English typists need almost none at all. So the keyboard layouts on a Motorola RAZR V3 for a [2] differ as follows:
German: a b c 2 ä
English: a b c 2
Bulgarian: а б в г 2
Serbian: a b c 2 а б в г
Croatian: a b c 2 č ć
Romanian: a b c 2 ă â
Slovenian: a b c 2 č
With this device, entering “22222” results in either “ä”, “a” (if you type in more characters than the keys allow, it starts at the beginning again), “2”, “а” (Cyrillic), “č” or “ă”, depending on the language. Needless to say, the language selection is different for each device. The Eastern European languages mentioned here, for example, do not exist on any other device.
But to top it off, I discovered with the Siemens units that if you select “Greek”, there is no longer an “abc” mode. This means: The state graphs developed above are not generally valid, but in case of doubt even language-specific! Fortunately for me, this Siemens Greek turned out to be the only exception in this respect. But for the sake of completeness, here is the, fortunately very simple, Greek graph for the A65, C75, ME45 and S55 (the S35 had no Greek mode):
Well, in the end, of course, the big goal was to integrate all this into the GC Wizard, which was actually achieved today after weeks of meticulous work:

Of course I realise that this function will virtually never be used. And precisely for this reason, the cost-benefit effort is rightly to be questioned. But this is where my personal demand for perfectionism kicked in, this is where the urge to research kicked in, this is where I was able to let off some great steam while the rest of the team is working on the super great pictures section (get excited, it’s going to be epic!)
And yes, please don’t have a heart attack, there will still be a “Simple Mode” to handle your multitap code as before 🙂
Finally, a word about the limits or boundary-crossings of the system described here:
- There is no LongPress (holding down a key for a long time). The classic telephone key code consists only of blocks of digits such as “111 22222” (plus any supplementary “#” or “*” characters). Our system cannot display a LongPress because the telephone key code does not define this. However, some devices have special functions, such as the direct writing of the respective digit, or even the switching of the writing modes on the LongPress. This function is of course missing here.
- The Motorola CD930 does not have a lower case write mode in our system. To enter this mode, you need the LongPress on the device. Since this is not supported, as described, there is no lower case in our simulator for this model.
- The Sagem My X-3 cannot type “B” or “C” or “E” or “F” or … with our system. type. The problem is that no “multitap” has been implemented on this device. Typing [2] several times writes “A” several times. The letter change takes place by means of LongPress, i.e.: hold the key until the desired letter appears. And since the LongPress is missing in the code and simulator, you can only type the first letters of the respective keys.
- Topic T9: Many will remember: When switching through the modes, you also end up in a T9 mode with some manufacturers (e.g. “Abc” -> “T9” -> “abc” -> “Abc”). Since we do not support T9, this was completely ignored in the overall system. This also means that a change from “Abc” to “T9” is ignored. So instead of the 2 mode changes (e.g. “##”) that would be necessary in real terms in our example to go from “Abc” to “abc”, only one mode change is needed (“#”). If we had made this even more realistic and observed T9, we would have been busy for months. Just getting authentic, device-specific T9 dictionaries proves to be an almost unbreakable hurdle.
- On some devices, [*] or [#] opens a kind of submenu for special characters. You can then use the arrow keys to select the respective character. Since we did not want to include arrow actions, this list of special characters was simply treated like a normal keyboard layout. So you need “*******” to write the seventh special character of this menu.
I hope you found it exciting to get a deeper insight into our work; to see what it can mean to develop a new function “just quickly”. I certainly had a lot of fun with it – but I’m also glad that I can close the chapter now 🙂